Ingestion and Retrieval Flows
Knowledge lets you configure how data is ingested and how it is retrieved back at querytime using flows. Flows are a series of steps that can be configured via simple YAML files - so-called Flow Files or Flow Configs.
Ingestion Flows
An Ingestion Flow consists of 3 main parts (all of them are optional and have basic defaults):
- Documentloader: The loader defines how input data/files are parsed and transformed to "LLM-readable" text.
- Textsplitter: The textsplitter defines how the text coming from the loader is split into smaller parts (documents).
- Transformers: Transformers can be used to modify the documents coming out of the textsplitter. They can e.g. add metadata, remove irrelevant documents or generate summaries for every document.
All the documents yielded by that flow will be sent to the Embeddings Model (globally defined, not yet configurable via flow file) and then stored in the vector database.
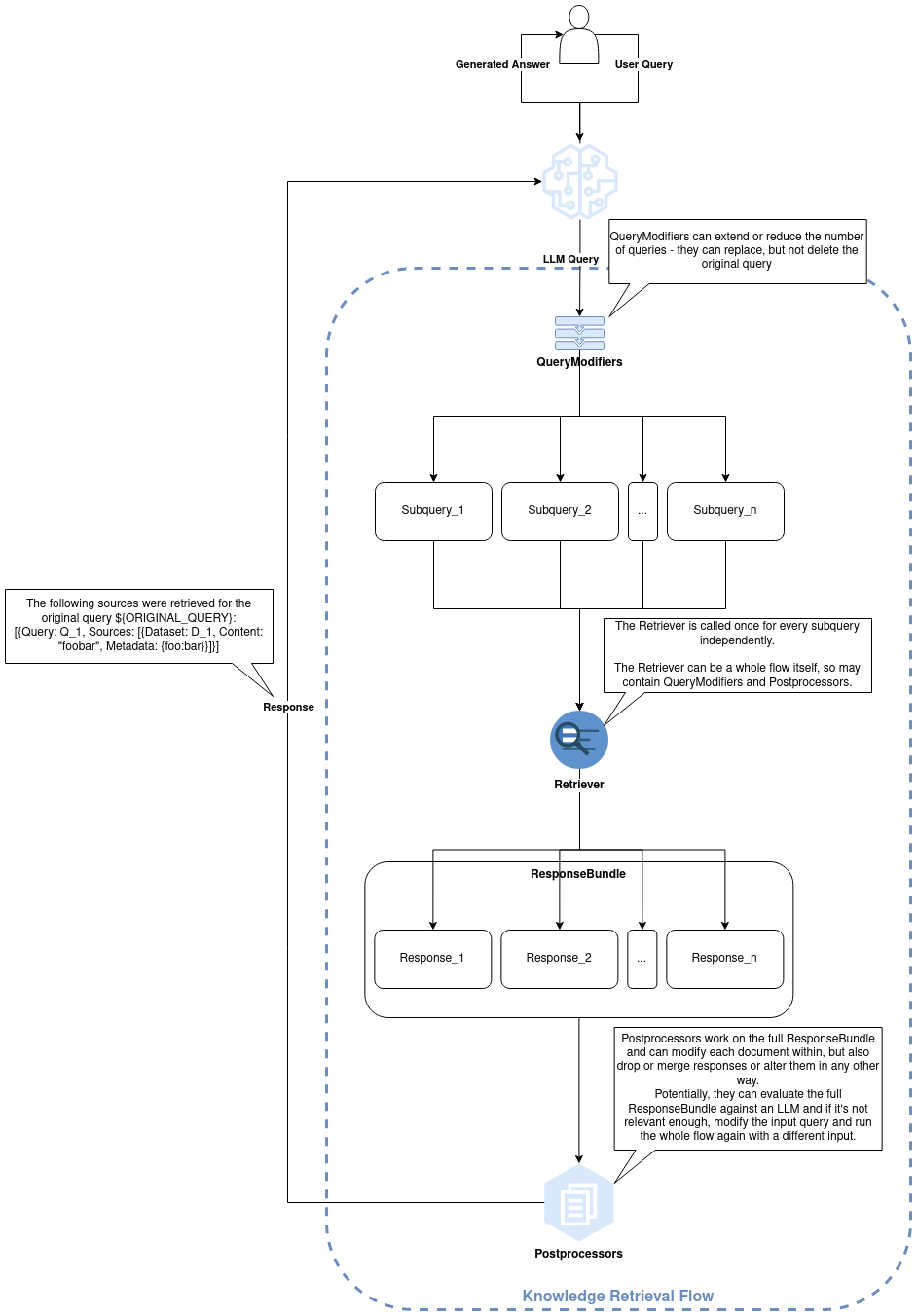
Retrieval Flows
A Retrieval Flow consists of 3 main parts (all of them are optional and have basic defaults):
- QueryModifiers: QueryModifiers can be used to modify the input query before it is used for retrieval. They can even generate additional subqueries.
- Retriever: The retriever defines how documents are retrieved from the vector database. E.g. one can use a routing retriever which automatically selects the most suitable dataset for the search.
- Postprocessors: Postprocessors can be used to modify the retrieved documents. They can e.g. filter out irrelevant documents or sort the documents by relevance.
Retrieval Flow Architecture
Flow Config File - "Flows File"
A Flows File can define one or more named flows and can even assign flows to datasets, so you don't have to manually select them everytime.
Using Flows Files
Use the --flows-file flag to point to your flows file and optionally the --flow flag to select a specific flow from that file for your operation.
If you don't specify a flow, either the dataset-assigned flow or, if there is no such assignment, the default flow will be used.
The --flows-file and --flow flags are available for the following commands:
ingestretrieveaskdir
File Structure
A Flows File is a YAML file with the following structure:
flows: # top-level key (required) - Define your flows here
foo: # name of the flow
default: false # optional - Set this flow as the default flow
ingestion: # define the ingestion flow
# List of ignestion flows - Ingestion flows can be defined for different filetypes
# Ingestion flows consist of a documentloader, textsplitter and one or more transformers
# All components are optional and have basic defaults
- filetypes: [".txt", ".md"]
documentloader:
name: plaintext
textsplitter:
name: markdown
transformers:
- name: filter_markdown_docs_no_content
- name: extra_metadata
options: # define advanced options for the extra_metadata transformer
metadata:
"foo": "bar"
- filetypes: [".pdf"]
documentloader:
name: pdf
options:
maxPages: 5
interpreterConfig:
ignoreDefOfNonNameVals:
- "CMapName"
retrieval: # define the retrieval flow
# There can be only one retrieval flow per top-level flow - there's no differentiation between filetypes
# The retrieval flow consists of querymodifiers, a retriever and postprocessors
# All components are optional and have basic defaults
retriever:
name: basic
options:
topK: 15
postprocessors:
- name: extra_metadata
options:
metadata:
"spam": "eggs"
bar: # another flow with only ingestion defined
default: false
ingestion:
- filetypes: [ ".txt", ".md" ]
documentloader:
name: plaintext
textsplitter:
name: text
baz: # another flow with only ingestion defined, which only differs from the `bar` flow in the chunkSize option
default: false
ingestion:
- filetypes: [ ".txt", ".md" ]
documentloader:
name: plaintext
textsplitter:
name: text
options:
chunkSize: 4096
datasets: # top-level key (optional) - Assign flows to datasets
foo: foo # dataset "foo" uses flow "foo"
bar: bar
baz: baz
Example Flows Files
You can find some example flow files in our GitHub repository.