Knowledge Architecture
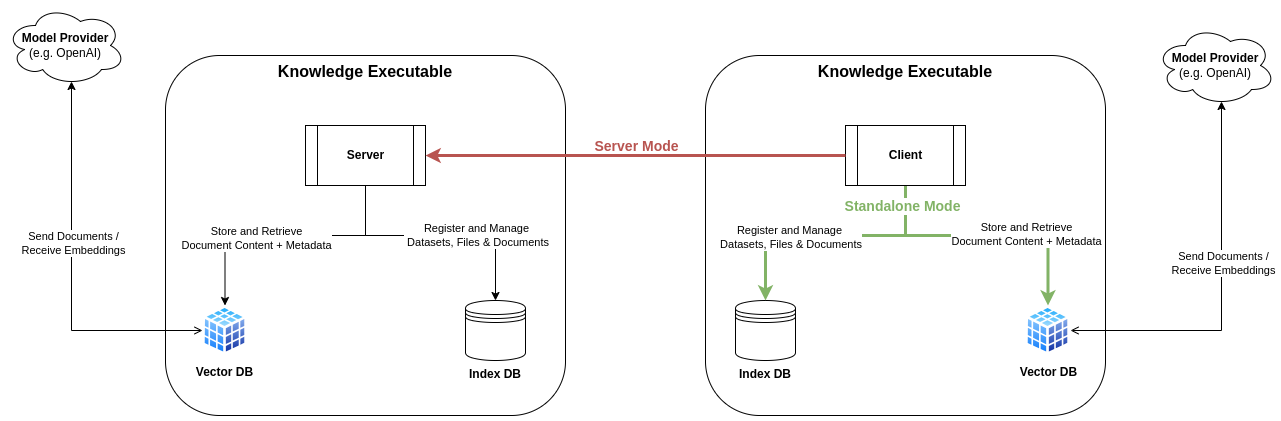
Knowledge consists of the following components:
1. Knowledge Client
The Knowledge Client is the main interface to interact with your knowledge bases. In standalone mode, it makes direct use of embedded databases. It's running fully locally. It's also the default entrypoint for the CLI.
2. Knowledge Server [Optional]
The Knowledge Server is a REST API server that can be used to provide a (shared) HTTP Endpoint for your knowledge bases.
You can make use of it in the CLI by setting the KNOW_SERVER_URL environment variables for all client commands.
3. Index Database
The index database is an additional (relational) metadata database which keeps track of all datasets and ingested files and their relationships. It enables some extra convenience features but does not store the actual data (content & embeddings). The current implementation uses SQLite by default, which is fully embedded and does not require any additional setup.
4. Vector Database
The vector database is the main storage for the content and embeddings of the ingested documents along with some metadata (e.g. source file information). The current implementation uses chromem-go by default, which is fully embedded and does not require any additional setup.